Welcome to the 7th Joint Statistical Meeting of the Deutsche Arbeitsgemeinschaft Statistik
24 to 28 March 2025 in Berlin, Germany
Statistics in times of AI
The 7th Joint Statistical Meeting of the Deutsche Arbeitsgemeinschaft Statistik will take place at Humboldt-Universität zu Berlin, Unter den Linden 6, 10099 Berlin, from 24 – 28 March 2025. It is hosted by Humboldt-Universität zu Berlin in close collaboration with Charité – Universitätsmedizin Berlin and Statistisches Bundesamt. We are looking forward to your participation at the DAGStat conference in 2025.
This year's DAGStat2025 conference will feature a variety of scientific sections, reflecting key areas of current research in statistics. Below is the list of sections that will be covered during the conference.
A detailed session plan is available here.
Furthermore, you can download the conference guide including detailed information about the event and scientific program here.
Program Overview
10 Biometry and Epidemiology
11: Causal Inference
12: Design of Experiments and Clinical Trials
13: Nonclinical Statistics
14: Statistical Methods in Epidemiology
15: Statistics in the Pharmaceutical and Medical Device Industry
16: Survival and Event History Analysis
20 Data Science, Machine Learning, and AI
21: Artificial Intelligence and Machine Learning
22: Clustering and Classification
23: Deep Learning + Statistics
24: Text Mining, NLP and Content Analysis
25: Time Series and Statistical Forecasting
26: Trustworthy Data Science
27: Visualisation and Exploratory Data Analysis
30 Statistical Applications
31: Bioinformatics and Systems Biology
32: Empirical Economics and Applied Econometrics
33: Marketing and E-Commerce
34: Statistics in Agriculture and Ecology, Environmental Statistics
35: Statistics in Finance
40 Statistical Theory and Methods
41: Advanced Regression Modelling
42: Bayesian Statistics
43: Mathematical Statistics
44: Meta-Analysis
45: Robust and Nonparametric Statistics
46: Testing and Scaling
50 Survey, Social Sciences, and Educational Statistics
51: Official and Survey Statistics
53: Statistical Literacy and Statistical Education
54: Statistics in Social, Behavioral and Educational Sciences
55: Structural Equation Modelling and Latent Variables
56: Survey Methodology
60 Special Topics
61: Extreme Values and Rare Events
62: Network Analysis
63: Spatial and Spatio-temporal Statistics
64: Statistical Software
65: Synthetic Data, Georeferencing & Disclosure Control
Sylvia Richardson is the Emeritus Director of the MRC Biostatistics Unit (BSU) at the University of Cambridge, where she served as Director from 2012 to 2021. During this time, she also held a professorship at Cambridge. Before joining the BSU, she was the Chair of Biostatistics at Imperial College London from 2000 and previously served as Directeur de Recherches at the French National Institute for Medical Research (INSERM), where she held research positions for 20 years. In 2019, Richardson was appointed Commander of the Most Excellent Order of the British Empire (CBE). She has also received the Royal Statistical Society’s Guy Medal in Silver and a Royal Society Wolfson Research Merit Award. Richardson is a Fellow of the Institute of Mathematical Statistics and the International Society for Bayesian Analysis.
David Blei
David Blei is a Professor of Statistics and Computer Science at Columbia University and a member of the Columbia Data Science Institute. He earned his Ph.D. in Computer Science from the University of California, Berkeley, in 2004. Following this, he spent two years as a Postdoctoral Fellow in the Department of Machine Learning at Carnegie Mellon University. From 2006 to 2014, he served as an Assistant and later Associate Professor in the Department of Computer Science at Princeton University. In 2014, he joined Columbia University as a Full Professor. Blei is an expert in Machine Learning and Bayesian Statistics, with research focused on Topic Models, Probabilistic Modeling, and Approximate Bayesian Inference.
Susan Murphy
Susan Murphy is the Mallinckrodt Professor of Statistics and Computer Science at Harvard University and an Associate Faculty member at the Kempner Institute for the Study of Natural and Artificial Intelligence at Harvard. She is a renowned expert in causal inference and the development of statistical methods for clinical trials targeting chronic and recurring diseases. Her work focuses on data-driven algorithms and methods for sequential decision-making in healthcare, such as real-time algorithms for optimizing personalized treatment sequences delivered via mobile devices.
Xiao-Li Meng
Xiao-Li Meng is a Professor of Statistics at Harvard University and the founding editor of the Harvard Data Science Review, a newly established journal in the field of data science. In 2001, he received the COPSS Award (Committee of Presidents of Statistical Societies) and has since garnered numerous accolades for his over 150 publications across various theoretical and methodological areas. Meng is also recognized for his contributions to education and training, and in 2020, he was elected to the American Academy of Arts and Sciences. His research interests span from the theoretical foundations of statistical inference (e.g., Bayesian, fiducial, and frequentist perspectives; frameworks for multi-source, multi-phase, and multi-resolution inference) to statistical methods and computation (e.g., posterior predictive p-values, the EM algorithm, and Markov Chain Monte Carlo methods), with applications in natural and social sciences, medicine, and engineering.
Invited Speakers
#
Section
Name
Institution
11
Causal Inference
Elise Dumas
EPFL Lausanne, CH
12
Design of Experiments and Clinical Trials
Anastasia Ivanova
U N Carolina, Chapel Hill, US
13
Nonclinical Statistics
Leonard Held
U Zurich, CH
14
Statistical Methods in Epidemiology
Anne Helby Petersen
U Copenhagen, DK
15
Statistics in the Pharmaceutical and Medical Device Industry
Philip Young
Biontech, Munich, DE
16
Survival and Event History Analysis
Morten Overgaard
Aarhus U, DK
21
Artificial Intelligence and Machine Learning
Luc de Raedt
KU Leuven, BE
22
Clustering and Classification
Marta Nai Ruscone
U Genoa, IT
23
Deep Learning + Statistics
Mihaela van der Schaar
U Cambridge, UK
24
Text Mining, NLP and Content Analysis
Benjamin Roth
U Vienna, AT
25
Time Series and Statistical Forecasting
Johanna Ziegel
ETH, Zurich, CH
26
Trustworthy Data Science
Eirini Ntoutsi
University of the Bundeswehr, Munich, DE
27
Visualisation and Exploratory Data Analysis
Dianne Cook
Monash U, AU
32
Empirical Economics and Applied Econometrics
Jörg Stoye
Cornell U, Ithaca, US
33
Marketing and E-Commerce
Daniel Guhl
HU Berlin, D
34
Statistics in Agriculture and Ecology, Environmental Statistics
María Xosé Rodríguez Álvarez
U Virgo, ES
35
Statistics in Finance
Michael Weber
U Chicago, US
41
Advanced Regression Modelling
Christel Faes
U Hasselt, BE
42
Bayesian Statistics
Antonio Pievatolo
IMATI, IT
43
Mathematical Statistics
Ingrid van Keilegom
KU Leuven, BE
44
Meta-Analysis
James Pustejovsky
U Wisconsin-Madison, US
45
Robust and Nonparametric Statistics
Marc Buyse
IDDI, Brussels, BE
46
Testing and Scaling
Wim van der Linden
U Twente, NL
51
Official and Survey Statistics
Monica Pratesi
ISTAT, Rome, IT
53
Statistical Literacy and Statistical Education
Travis Weiland
U N Carolina, Charlotte, US
54
Statistics in Social, Behavioral and Educational Sciences
Jennie Brand
UCLA, US
55
Structural Equation Modelling and Latent Variables
Andreas M. Brandmaier
Medical School, Berlin, DE
56
Survey Methodology
Peter Lugtig
Utrecht, NL
61
Extreme Values and Rare Events
Philippe Naveau
LSCE, Gif-sur-Yvette, FR
62
Network Analysis
Philip Leifeld
U Manchester, UK
63
Spatial and spatio-temporal Statistics
Arkajyoti Saha
UC Irvine, California, US
65
Synthetic Data, Georeferencing & Disclosure control
Monday is Tutorial Day. There are Morning Tutorials, Afternoon Tutorials and Full Day Tutorials:
Note: The teacher's day will take place in parallel with the tutorials.
Morning Tutorials
Target trial emulation and causal inference for time-dependent treatments
Vanessa Didelez, Malte Braitmaier and Bianca Kollhorst (BIPS Bremen, Germany)
Using routinely collected data (or real-world data) to answer questions about (long-term) effectiveness or safety of drugs or preventive measures bears sources of potential bias, besides confounding. These are termed “self-inflicted” biases because they can be minimised by careful study designs. Target trial emulation (TTE) is an increasingly popular principle to facilitate the formulation of the causal estimand and determine a suitable designs. However, lack of familiarity with statistical techniques and software may deter researchers from actually using TTE. Moreover, typical analyses are often limited to ITT-type emulation even if the intended use of drugs or treatments is sustained or adaptive. This course therefore aims to address and demonstrate practical aspects and implementation of TTE specifically for time-dependent treatments. In particular, we will cover techniques of “sequential target trials”, “artificial censoring & weighting” and “cloning” to avoid, e.g., immortal time or prevalent user and similar types of bias.
Some basic knowledge of methods for causal inference will be helpful but is not strictly required. Exercises will be "pen and paper" (or their electronic equivalents).
Social Media and Statistics - How Do They Fit Together?
Alexander Schacht (The Effective Statistician, Sanevidence GmbH, Germany)
In today's digital age, social media platforms, especially LinkedIn, offer unprecedented opportunities for statisticians and researchers to enhance their visibility, engage with a broader audience, and foster a community centered around their work. However, leveraging these platforms effectively requires more than just self-promotion; it involves a strategic approach to content creation and networking that emphasizes value and collaboration.This workshop, "Social Media and Statistics - How Do They Fit Together?" aims to bridge the gap between the statistical community and the potential of social media. Participants will learn how to use social media not just as a tool for sharing research but as a platform to build a supportive network, receive valuable feedback, and contribute to the broader scientific community.
Participants should bring a laptop and smartphone for interactive exercises.
Generalized pairwise comparisons: A practical guide to the design and analysis of patient-centric trials
Johan Verbeeck (U Hasselt, Belgium), Brice Ozenne (U Copenhagen, Denmark)
When assessing the effects of a treatment in clinical trials, often several clinical meaningful endpoints are simultaneously of interest. Yet, standard methods of analysis for multiple endpoints are limited in a number of ways. The generalized pairwise comparisons (GPC) methods form a very flexible class of non-parametric techniques for prioritized endpoints, which overcome all of these limitations. Major advantages are interpretability, the individual-level patient-centric analysis, and good small sample properties.
In this course, we provide an introduction to the framework of GPC, focusing on practical solutions for the design and analysis of clinical trials with examples in cardiology, oncology and rare diseases, followed by a Q&A for the remainder of the session. Interested participants will be able to apply the GPC methodology on provided datasets with the aid of a user-friendly R package on their own computer, shared through the open science framework platform.
The course is aimed at statisticians, clinicians and trialists from academia, industry and regulatory agencies with knowledge on clinical trials, who want to learn more about the GPC statistical methodology for multiple endpoints of potentially different data types in large and small sample trials. No specific hardware knowledge is required. Participants are encouraged to bring a personal computer with R pre-installed and the BuyseTest package installed from CRAN.
Reproducible Research in R: How to Do the Same Thing More Than Once
Aaron Peikert, Maximilian Ernst, Hannes Diemerling (Formal Methods Group at Max Planck Institut for Human Development, Germany)
Computational reproducibility is the ability to obtain identical results from the same data with the same computer code. The high rate of irreproducible research limits the reach of results and decreases the efficiency of researchers. Reproducible research is a building block for transparent and cumulative science because it enables the originator and other researchers, on other computers and later in time, to reproduce and thus understand how results came about. Many researchers want to work reproducibly, but it is not easy. Considerable time is required to acquire the skills required for reproducible research, and the path is lined with pitfalls. This workshop gets researchers up to speed on how to create reproducible data analyses in R (and beyond). Specifically, researchers learn to automate the whole process from raw data to publishable manuscripts. This automation is possible by combining dynamic document generation (via R Markdown/Quarto), version control (via Git), workflow orchestration (via Make) and software management (via Docker). These tools and, therefore, automatic reproduction of results are available on any machine with Docker installed. The resulting workflow is, hence, highly transferable across machines and time. These core properties of reproducibility are demonstrated for any reader by automatically reproducing the manuscript online.
Afternoon Tutorials
Enhancing your Code: Combining R and C++ via Rcpp and RcppArmadillo
Many researchers rely on simulation studies and complex computations demonstrate properties of their methods. While R is a widely used language for statistical computing, its interpreted nature can limit performance for intensive and repetitive computations. On the other hand, C++, a compiled language, offers faster execution but requires more programming expertise. This tutorial aims to provide basic knowledge to C++ programming and demonstrates how to integrate C++ code into R using the R packages Rcpp and RcppArmadillo. By leveraging C++'s low-level efficiency, researchers can substantially accelerate their computations. Content: 1. Basics of C++; 2. The Armadillo-Library; 3. Importing C++ Code into R; 4. Practical Examples; 5. Parallelization of C++ Code.
Participants are required to bring their own notebooks with R, Rtools, and the R-Packages "Rcpp"" and "RcppArmadillo" installed. Participants should have a working knowledge of R programming concepts, such as loops, conditional statements, and user-defined functions.
Nonparametrics: Some basics and new developments - common misunderstandings, pitfalls, and surprising results
Edgar Brunner (University Medical Center Göttingen, Germany) und Georg Zimmermann (U Salzburg, Austria)
What does it actually mean when the hypothesis of a nonparametric test is being rejected? Which alternatives do the different nonparametric and related parametric hypothesis tests really detect? When using inferential methods, it is important to understand the meaning of the so-called consistency region of a test. Misinterpretations might easily happen if this concept is not considered, in particular if the underlying statistical model has restrictions.
It is the aim of this tutorial to explain the basics, as well as surprising and paradoxical results obtained from different nonparametric procedures – offered in several R-packages – by means of many examples, and to demonstrate possible misinterpretations and misuses of them. We consider (among others) the tests of Mann-Whitney, Kruskal-Wallis, Akritas-Arnold-Brunner, Brunner-Konietschke-Pauly-Puri, Munzel-Hothorn, Jonckheere-Terpstra, Hettmansperger-Norton, van-Eletren, sign-/Wilcoxon-signed-ranks, Friedman, Kepner-Robinson, and Akritas-Brunner.
Participants are expected to have a solid understanding of statistical inference, including a working knowledge of basic nonparametric, rank-based methods.
Variable selection and prediction modelling for high-dimensional genomic data
Christian Staerk (TU Dortmund, Germany), Hannah Klinkhammer (IMBIE, U Bonn, Germany)
High-dimensional biomedical data with many genetic, environmental and clinical variables require scalable and interpretable statistical learning methods for variable selection and prediction. In particular, polygenic risk scores are derived from large cohort studies that include many participants and genetic variants to quantify genetic predispositions for traits and diseases. In the first part of this tutorial, we provide an overview of variable selection and prediction methods for high-dimensional data (large p), including the lasso and its variants, information criteria and boosting. We will also discuss challenges of data-driven variable selection in biomedical research. In the second part, we explore scalable methods for modelling individual-level data from large cohort studies like the UK Biobank, consisting of hundreds of thousands of genetic variants and individuals (large p and n). Specifically, we present frameworks for applying regularized regression via the lasso and statistical boosting for polygenic risk score modelling on large-scale genomic datasets. Our tutorial will include practical exercises in R.
Participants are asked to bring their laptops with an R installation and ideally also have some prior experience with R.
Full Day Tutorials
Distributional Regression – Models and Applications
Nadja Klein (Karlsruhe Institute of Technology, Germany) and Lucas Kock (NU Singapur)
This tutorial, structured into two three-hour blocks, provides an interactive exploration of distributional regression, building on the foundational concepts of generalized linear and additive models. Participants will obtain a review of various distributional regression models and their applications, highlighting the advantages of modeling entire response distributions over traditional mean regression. The session will include hands-on exercises using R, with a focus Bayesian Additive Models for Location Scale and Shape and distributional regression for univariate responses and its extensions to multivariate responses. Through practical exercises and real-world illustrations, participants will gain insights into when and how to apply these models effectively. By the end of the workshop, attendees will have a solid understanding of distributional regression principles and practical skills in model building, estimation, and interpretation.
Participants should bring their laptop with a running and recent version of R installed. Participants are assumed to be familiar with basic R syntax and have ideally experience with conducting linear or additive regression models in R.
An introduction to estimands and estimand-aligned estimation
Tim Friede (U Göttingen, Germany), Tobias Mütze (Novartis), Vivian Lanius (UCB Biosciences GmbH) and Norbert Benda (BfArM, Germany)
Defining scientific questions in a clinical trial is essential for its design, conduct, analysis, and interpretation. Challenges in clarifying treatment effects led to the ICH E9(R1) addendum on estimands and sensitivity analysis in clinical trials. This addendum provides a framework to define treatment effects, or estimands, before choosing aligned statistical methods.
The first part of this course introduces concepts from the ICH E9(R1) addendum, including estimands, intercurrent events and their handling strategies, missing data, and sensitivity analyses. Practical aspects such as discussing estimands in teams, describing them in protocols, and reporting results will be covered. Perspectives of clinical trialists and regulatory assessors will be addressed. This part includes interactive group work. The second part focuses on identifying and implementing analysis approaches aligned with a chosen estimand using an example. The implementation of various approaches will be illustrated through exercises in R.
Participants should be familiar with the basic principles of clinical trials, including their design, and conduct, and common analysis methods. Additionally, participants must have R Version 4.3.0 or higher installed, along with the R packages tidyverse, rbmi, and rstan.
From Theory to Practice: Vine Copula Models
Claudia Czado, Ariane Hanebeck, Ferdinand Buchner (TU München, Germany) and Özge Şahin (TU Delft, The Netherlands),
As the availability of complex multivariate data continues to grow, understanding dependence structures becomes increasingly important. Copulas play a key role in this exploration. However, standard copula models often fall short when capturing flexible dependence patterns and tail behaviors. To address these limitations, (simplified) vine copula models (vine-copula.org) were developed, offering enhanced flexibility and the ability to model asymmetric tail dependence. In this tutorial, we’ll start with the basics of copulas and vine copulas. We’ll then demonstrate how vine copulas build flexible multivariate regression models, focusing on univariate and bivariate responses. Practical application sessions will use R libraries like rvinecopulib and vinereg to explore real-world scenarios such as probabilistic weather forecasting and financial stress testing. By the end, participants will understand both the theory and practice, equipping them to apply vine copula-based methods in their work.
Participants are expected to have a basic knowledge of R and RStudio and an interest in statistical modeling and data analysis. Please ensure that you bring a laptop with the latest versions of R and RStudio installed.
This tutorial provides a hands-on introduction to machine learning using R and the powerful mlr3 ecosystem. Designed for intermediate and experienced R users, the session covers fundamental machine learning concepts, workflows, and practical applications. Participants will learn how to train and evaluate supervised machine learning models, tune hyperparameters, perform benchmark experiments, and implement pipelines using mlr3's modular and extensible framework. The tutorial emphasizes reproducibility and efficient coding practices, showcasing how mlr3 integrates seamlessly with other R tools for data analysis. By the end of the session, attendees will be equipped with the skills to implement and interpret machine learning models in real-world projects. No prior experience in machine learning is required, though familiarity with R is recommended.
Participants should have (at least) a basic knowledge of R and bring a laptop with recent versions of R and the mlr3verse package or access to R in the cloud, as well as their favorite IDE, e.g., RStudio.
Bayesian Data Analysis
Javier Enrique Aguilar and Luna Fazio (TU Dortmund, Germany)
This workshop provides an introduction to the contemporary Bayesian workflow: participants will learn the core concepts that motivate the use of Bayesian inference, the computational tooling that enables one to work within this framework, and a set of practical guidelines to verify that the resulting models provide reliable inferences. Specific statistical methods that will be covered include basic linear regression, generalized linear models, hierarchical models, and prior specification. We will also discuss visualization and communication of results. Additional specialized topics may be covered based on participant interest and time availability
Participants should be familiar with basic probability concepts (joint, conditional and marginal probabilities, expectation of a random variable and probability distributions). Prior experience with linear regression will be beneficial. To follow along with the exercises, participants should bring a personal laptop with a recent version of R (4.2 or higher) installed. Ideally, the rmarkdown, tidyverse, rstan and brms packages should also be installed beforehand.
Program Overview
under construction
Emil Julius Gumbel
As part of this year’s conference, we are pleased to feature a special exhibition on Emil Julius Gumbel (1891-1966).
This Gumbel exhibition, entitled "Emil J. Gumbel - Statistiker, Pazifist, Publizist. Im Kampf gegen Extreme und für die Weimarer Republik", was created and designed by a team of scholars under Matthias Scherer (TU Munich).
Gumbel was a German statistician known for his political activism and pacifism. His work on extreme values and the Gumbel distribution named in his honor continue to be influential in many fields today. Combining his statistical knowledge and political advocacy, he published the book “Vier Jahre politischer Mord (Four years of political murder)” in 1922, showing the judiciary system of the Weimar Republic to be heavily biased in favor of right-wing extremists.
His continued outspoken engagement against fascism led to him being forced out of his tenure at the University of Heidelberg in 1932 after the “Gumbel riots” instigated by the National Socialist German Student League. After Jewish-born Gumbel moved to Paris with his family, his works were subject to Nazi book burnings. In 1940 he escaped from France to New York where he first became professor at the New School for Social Research. From 1953 on he was affiliated with the Columbia University.
Gumbel’s legacy is well-documented in scholarly works such as the proceedings of the Gumbel Symposium held in Heidelberg in 2019 (Runde/Scherer, 2022) and the exhibition catalog exploring his multifaceted contributions as a statistician, pacifist, and public intellectual (Scherer/Vogt, 2024).
In times of increased political division and resurgence of anti-democratic sentiment, it is ever more important to keep the legacy of anti-fascist activists alive. At Humboldt-Universität zu Berlin and Charité - Universitätsmedizin Berlin, we are committed to the values of democracy and respectful coexistence. We are against exclusion and hatred.
The exhibition will be open from 24 March - 11 May 2025. We’re looking forward to sharing this very special experience with you and encourage all conference attendees to join us at:
Lichthof (Ost) / Ausstellungsraum
Humboldt-Universität zu Berlin
Hauptgebäude, Erdgeschoss
Unter den Linden 6, 10117 Berlin
Young Statisticians
At the DAGStat 2025 in Berlin, the Early Career Working Group (AG Nachwuchs) of the IBS-DR will once again organize a Young Statisticians Session (YSS).
In this session, early career statisticians will present their projects in a friendly atmosphere and have the opportunity to receive feedback on their presentations (including style, content, slide design, etc.). The awarded Young Statisticians will receive a certificate and will be invited to the conference dinner. Additionally, their conference fee will be waived. The application deadline is 10 November 2024. Further information can be found in the attached flyer.
For questions regarding the application process, the AG Nachwuchs is happy to help at ag-nachwuchs@googlegroups.com.
Flyer
Lehrkräftetag (Teacher's Day)
Please note that this event is an offer for teachers in Germany. Hence, the following information and the program itself are provided in German.
Für interessierte Lehrkräfte: Die Teilnahme am Lehrkräftetag ist kostenlos möglich und für wird für Lehrkräfte aus Berlin und Brandenburg offiziell als Lehrkräftefortbildung anerkannt (hierzu ist eine zusätzliche Anmeldung über die Landesinstitute erforderlich; nähere Informationen erhalten Sie über die Anmeldung über das eMail-Anmeldeformular).
Das Programm und den Inhalt der Workshops entnehmen Sie bitte unten stehendem Flyer.
Note: The tutorials will take place in parallel with the teacher's day.
Statistics for the Public / Statistik für die Öffentlichkeit
On Monday, 24 March 2025 from 7:00pm to 8:30pm, Gerd Gigerenzer (director emeritus at the Max Planck Institut für Bildungsforschung; Section: "Adaptives Verhalten und Kognition") will give a talk in the context of "Statistics for the Public" in the Fritz Reuter Saal (Dorotheenstraße 24, 10117 Berlin). The talk will be held in German and the abstract is provided below:
Wie kann man Ärzten und Patienten helfen, Gesundheitsstatistiken zu verstehen?
Viele Ärzte, Patienten, Journalisten und Politiker verstehen Gesundheitsstatistiken nicht. Noch schlimmer, die meisten bemerken dies nicht einmal. Kollektiver statistischer Analphabetismus bezeichnet die weit verbreitete Unfähigkeit, die Bedeutung von Zahlen zu verstehen. Beispielsweise wissen viele Ärzte nicht, dass höhere Überlebensraten bei Krebsfrüherkennung nicht längeres Leben bedeuten, oder dass die Aussage, dass Mammographie-Screening das Risiko, an Brustkrebs zu sterben, um 20% reduziert, tatsächlich bedeutet, dass 1 Frau von 1.000 weniger an der Krankheit stirbt.
Die Ursachen für statistischen Analphabetismus liegen unter anderem in der unzureichenden Vermittlung statistischen Denkens in der medizinischen Ausbildung, der emotionalen Dynamik der Arzt-Patient-Beziehung und den Interessenkonflikten innerhalb der Gesundheitsbranche. Solche Konflikte führen regelmäßig dazu, dass Informationen – sowohl in Patientenbroschüren als auch in medizinischen Fachzeitschriften – absichtlich so formuliert werden, dass die Vorteile von Interventionen übertrieben und ihre Risiken heruntergespielt werden.
Dieses seit lange existierende Problem hätte eine Lösung. Unsere Studien zeigen, dass bereits wenige Stunden gezieltes Training das Verständnis von Gesundheitsstatistiken bei Ärzten und Medizinstudenten erheblich verbessert. Techniken wie die Verwendung von natürlichen Häufigkeiten statt bedingten Wahrscheinlichkeiten oder absoluter Risiken anstelle relativer Risiken erweisen sich als besonders effektiv. Die Verbesserung der statistischen Kompetenz ist unerlässlich – nicht nur für eine informierte Einwilligung im Gesundheitswesen, sondern auch für die Förderung mündiger Bürger in einer technologischen Demokratie.
Eine Teilnahme an diesem Vortrag ist auch für Personen kostenlos möglich, die nicht als Tagungsteilnehmer angemeldet sind.
Scientific Committee
The scientific committee consists of representatives of the member societies of the German Consortium in Statistics:
Sessions will take place in the following buildings of the Humboldt-Universität zu Berlin:
Main Building: Unter den Linden 6, 10117 Berlin
Room Code UL6-nxxx
n: Level; Level 1 = Ground Floor
nxxx: Room number
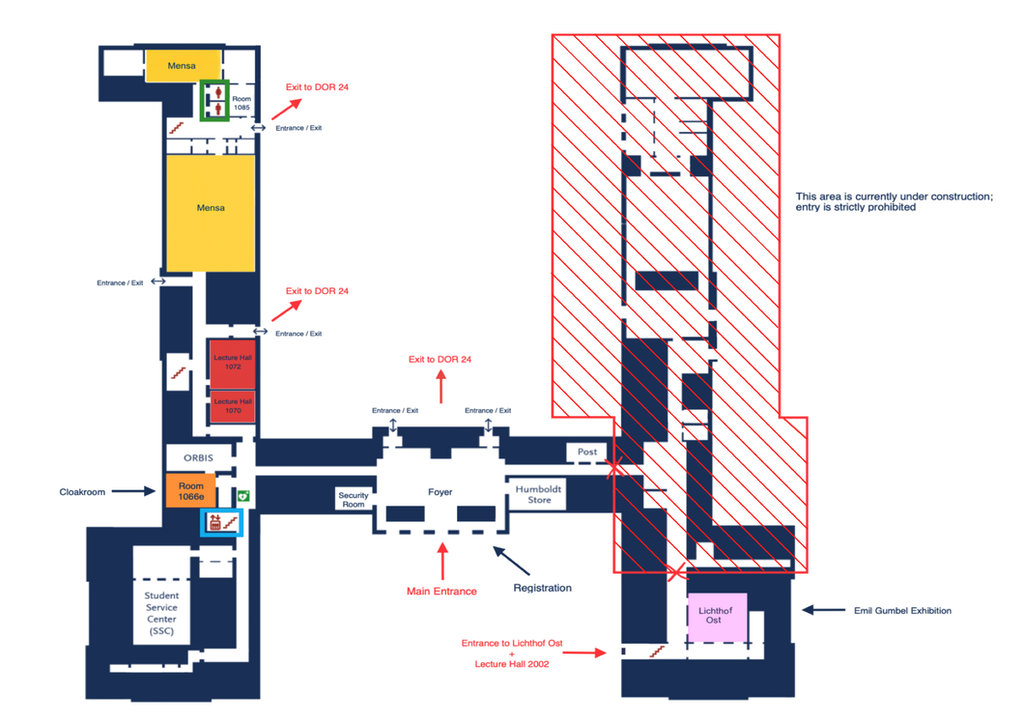
Due to ongoing construction, Lichthof Ost and Lecture Hall 2002 are not connected to the rest of the building. Lichthof Ost and Lecture Hall 2002 are accessed by a separate entrance located on the right-hand side of the building, as indicated on the map (Ground Floor / Outside). Please note that there is no elevator access to Lecture Hall 2002.
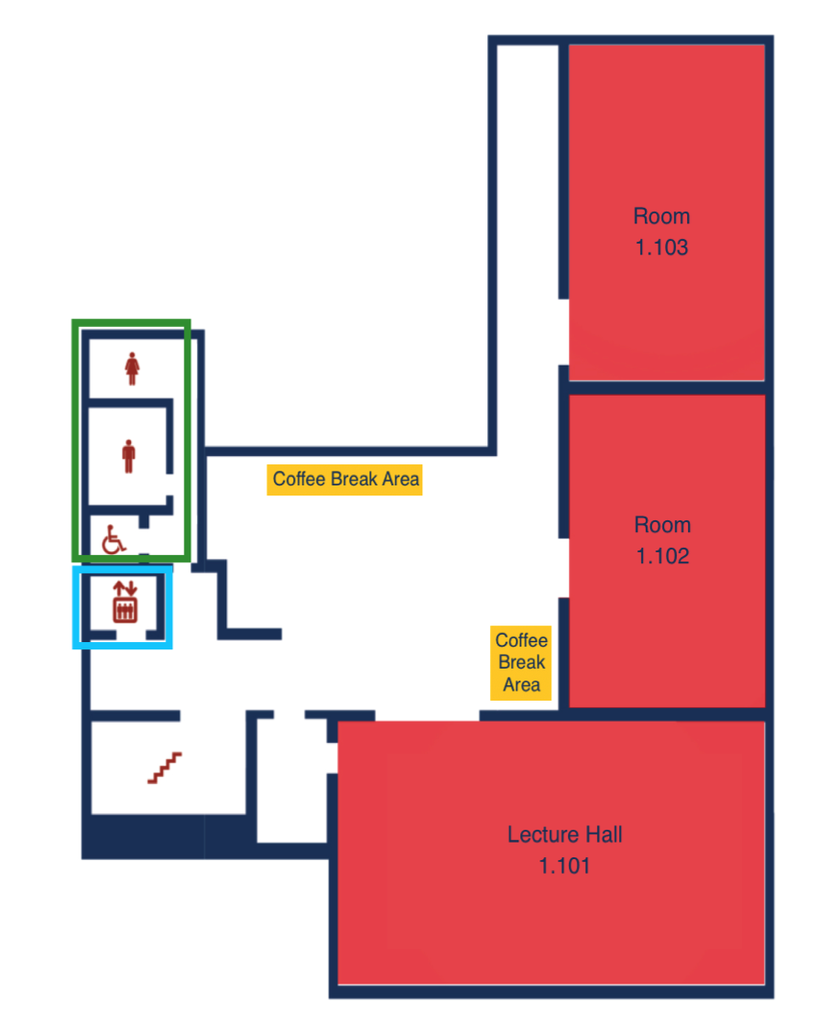
UL6 Level 1
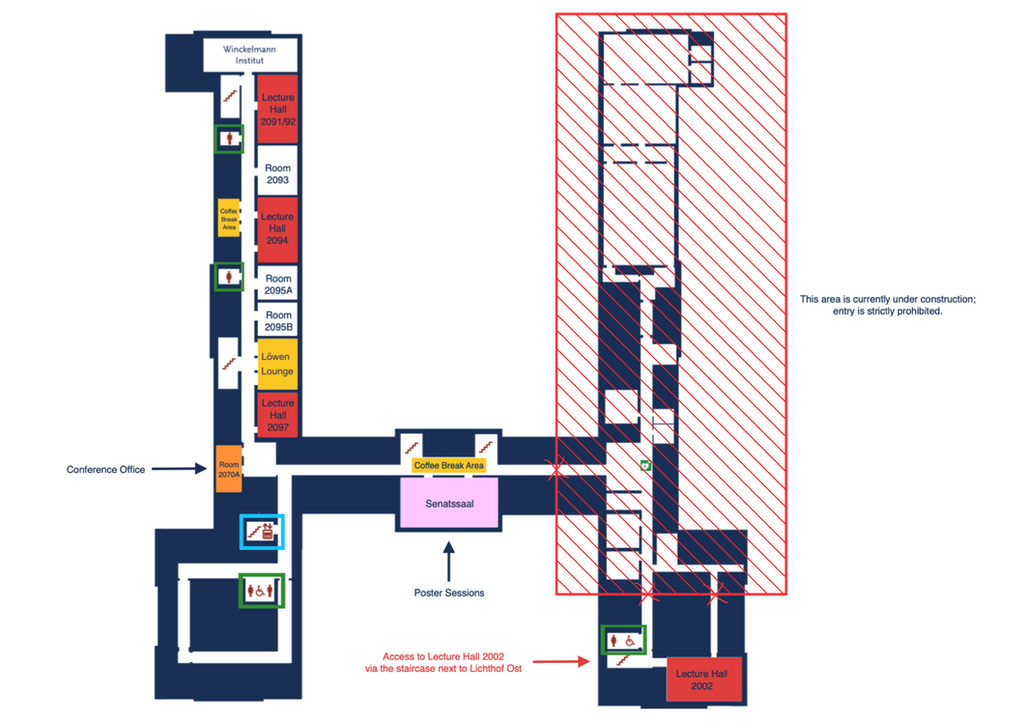
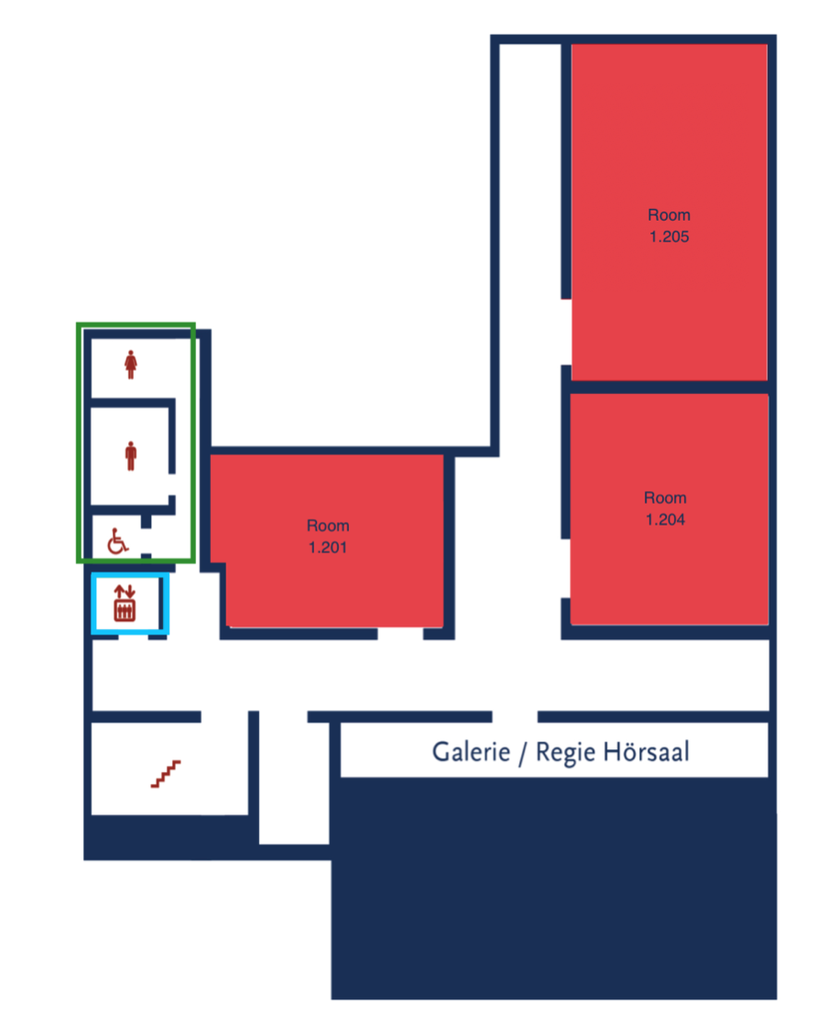
UL6 Level 2
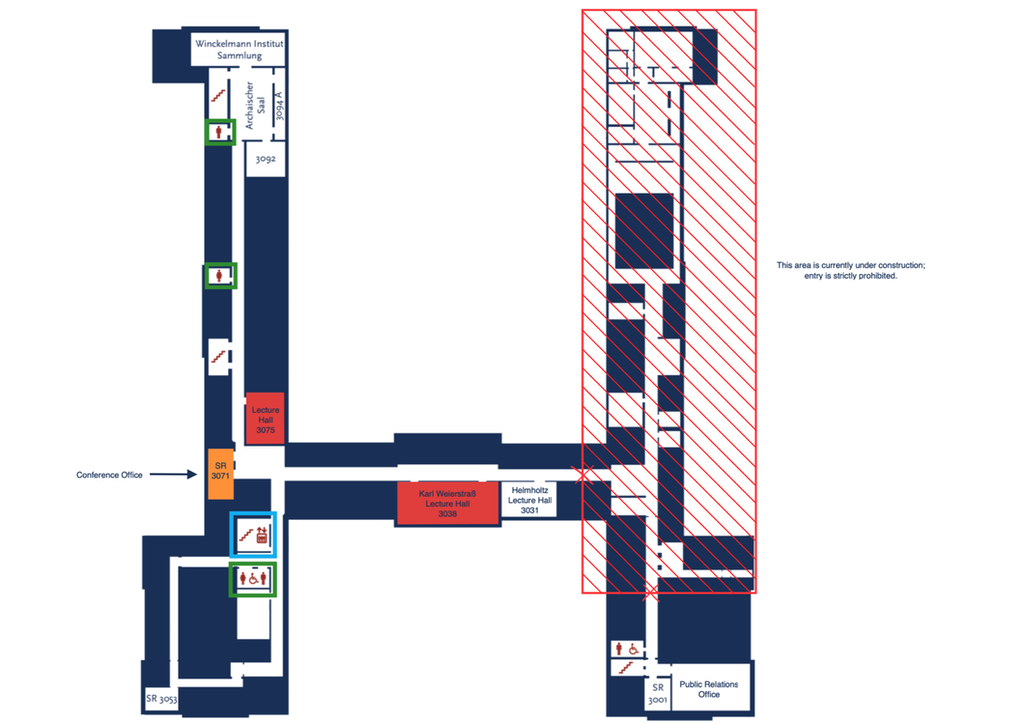
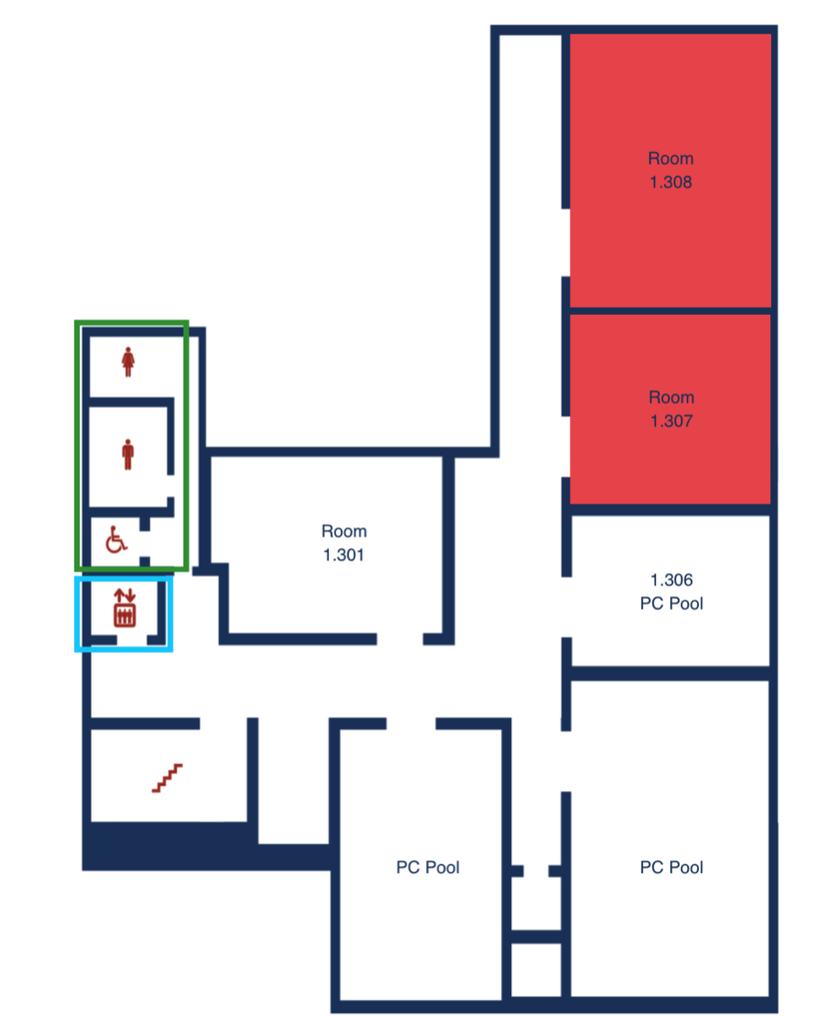
UL6 Level 3
University Building at Hegelplatz: Dorotheenstraße 24, 10117 Berlin
Room Code DOR24-m.nxx
m: Building number (Haus)
n: Floor
m.nxx: Room number
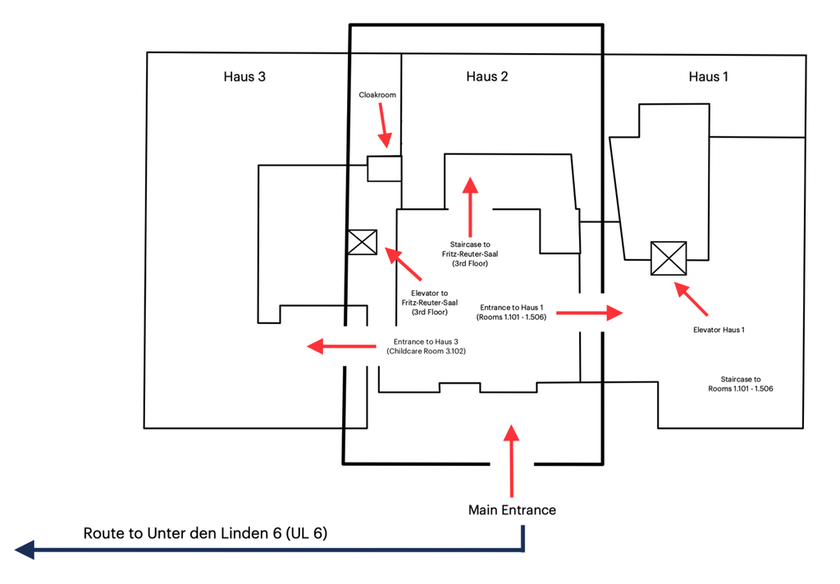
DOR24-FR : Haus 2, Fritz-Reuter-Saal
To access the Fritz-Reuter-Saal, please use the stairs or the elevator in Haus 2 and proceed to the 3rd floor.
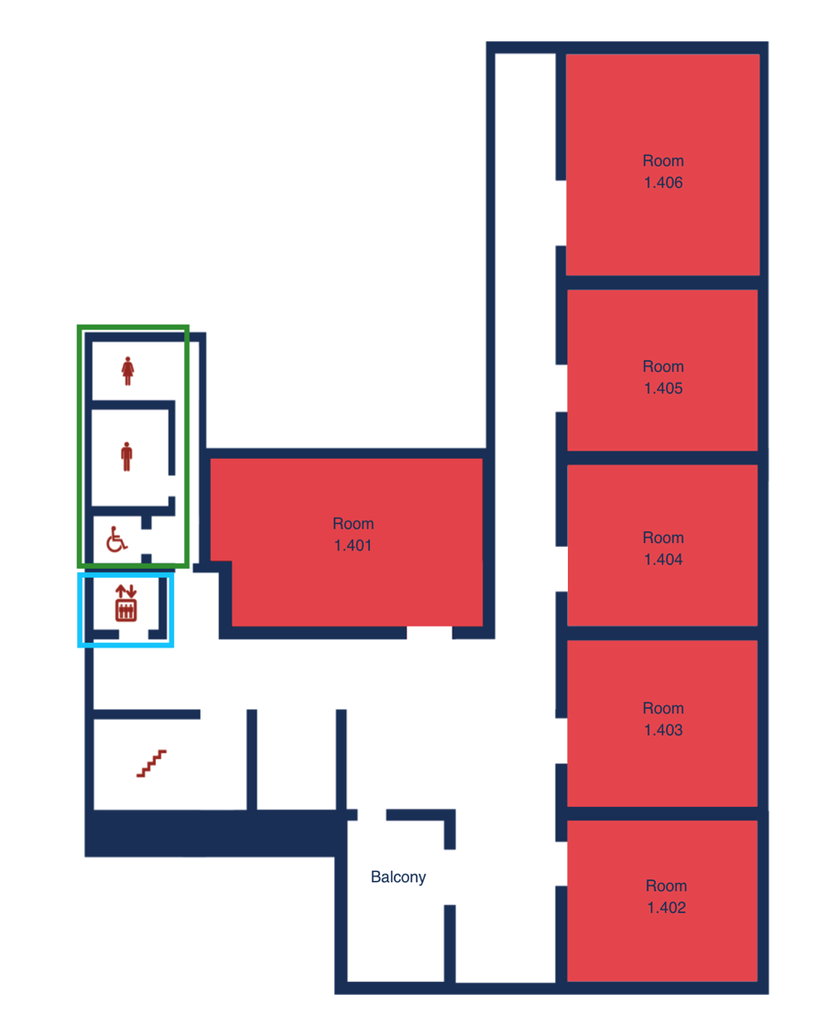
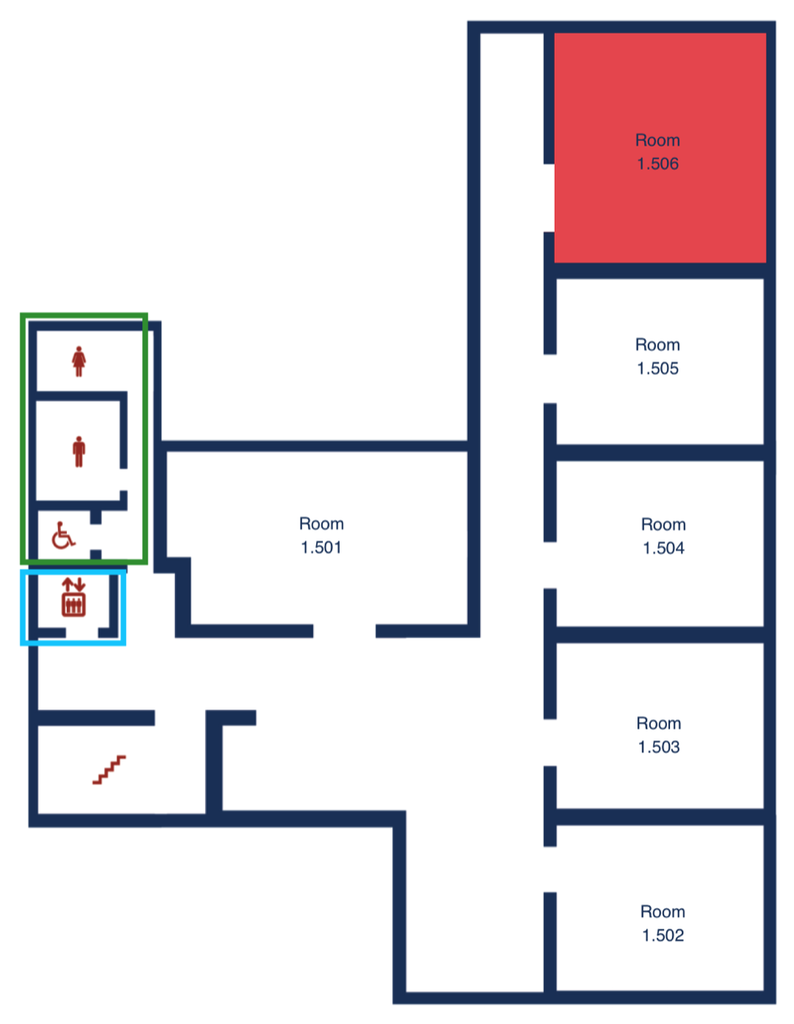
To access 1.101–1.506, take a right at the main entrance of DOR 24 and enter Haus 1 (as indicated on the map).
You may use either the stairs or the elevator in Haus 1 to reach your desired room.
Overview
DOR24 1st Floor
DOR24 2nd Floor
DOR24 3rd Floor
DOR24 4th Floor
DOR24 5th Floor
Color Code
DAGStat 2025 is an event hosted by Humboldt-Universität zu Berlin and managed by Humboldt-Innovation GmbH
Conference Fees
Conference Fees*
Note: Speakers are asked to register by 31 January 2025
main component and two side dishes or complete dish
a dessert or fruit
a non-alcoholic cold drink
13.50 €
13.50 €
13.50 €
13.50 €
* you will be billed by Converia GmbH, Kaufstraße 2-4, 99423 Weimar, Germany. Extra fees will be charged for use of credit cards (+0,5% of the invoice total) and PayPal (+1% of the invoice total) 1 we reserve the right to ask for proof. 2 member of one of the DAGStat cooperating societies. 3 Bachelor-, Master- and doctoral (PhD) students. 4 fee is for food and drinks. 5 bookable until 16 March 2025, 11:59pm. 6 bookable until 9 March 2025, 11:59pm.
Child Care
In case you need child care during the conference, use this form to contact us.
Teacher's Day
The Teacher's Day is free of charge. However, an extra registration for teacher's day required. Please see page teacher's day for more details.
details on the main conference sections can be found on the conference program page
Review
after submission ends
end of 2024
1 "abstracts" are called "paper" in the conference tool. 2 A submission can be either an “oral presentation” or a “poster”. 3 Please note that only one abstract per presenter is permitted. If a presenter submits several abstracts, we reserve the right to pick one of the submitted abstracts. The issue of someone not being able to submit an abstract because they are already the co-author of another abstract has been solved.
Registration
From
To
Early bird
to be announced
10 January 2025
Regular registration
11 January 2025
24 February 2025
Late/On-site registration
25 February 2025
Note: Speakers are asked to register by 31 January 2025
Frequently Asked Questions
Conference Tool
Question
Answer
I cannot find the "Login" on the Conference Tool start page on my smartphone. Where is it?
In small browser windows (e.g. on a smartphone), the Conference Tool start page will not feature a button "Login". Instead, located on top of that page, there is a square holding a person’s icon in a circle. Click that square to access button "Login".
When submitting an abstract, why do I have to enter all the co-author infos even though that author might be already known to the Conference Tool?
Enabling to choose from a list of authors known to the Conference Tool would result in a list of authors being published, which does not comply with data privacy laws.
I tried to submit an abstract, but was not allowed, because the Tool tells me "You have
already reached the maximum amount of papers."
The issue of someone not being able to submit an abstract because they are already the co-author of another abstract has been solved. However, only one abstract per presenter is permitted. If a presenter submits several abstracts, we reserve the right to select one of the submitted abstracts.
The handling of PDFs on a website is determined by the individual setting per user per web-browser. You can specify how to handle PDFs on websites in the respective web-browser settings.
Sessions
Question
Answer
If my abstract gets accepted for an oral presentation, how long will my presentation be?
Plan a maximum of 20 minutes (invited speakers: 40 minutes) for your presentation, including discussion.
Conference Flyer
Sponsoring
Funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) – project number
554746237.
We gratefully acknowledge sponsorship from:
Welcome Reception
A Welcome Reception will take place on Tuesday, 25 March 2025 from 7pm to 9pm in the Octogon (Leipziger Platz 14, 10117 Berlin). Please make reservations when registering for the conference.
The Welcome Reception will include a scientific talk - accompanying the Gumbel exhibition - by Prof. Dr. Annette Vogt, Max Planck Institute for the History of Science (MPIWG) and Humboldt-Universität zu Berlin, on: Emil J. Gumbel - Statistician, political author, and political activist.
Conference Dinner
The conference dinner will take place at the Eventlocation Wasserwerk (Hohenzollerndamm 208a, 10717 Berlin) on Thursday, 27 March 2025 at 7:30pm. Please make reservations when registering for the conference.
Student to Student City Tour
Join us for a tour around some of Berlin’s historic sites near the conference venue. The tour spans centuries of history and includes fascinating landmarks like the Humboldt Forum, Museum Island, and the striking Red City Hall. We will start at Bebelplatz, just in front of Humboldt University, cover a distance of about 2.5 km, and finally end at the vibrant Hackesche Höfe, where we can give you tips on further places to visit or fantastic restaurants nearby.
Meet new people, learn exciting and fun facts about our city, and get closer to your daily goal of 10,000 steps — all in just about 1 hour.
The guided tour is planned "from students for students" in two batches
on Tuesday, March 25, 2025 from 6:45pm to 7:45pm.
on Thursday, March 27, 2025 from 4:45pm to 5:45pm.
Please make reservations when registering for the conference.
Junior Meets Senior
Join us for an enjoyable and interactive evening at Junior Meets Senior, where doctoral students and early-career statisticians can connect with experienced researchers, invited speakers, and senior colleagues from academia and industry. This is a fantastic opportunity to expand your professional network in a relaxed setting.
The evening will feature a lively quiz with both trivia and statistics-related questions, where participants will compete in teams, along with delicious food and drinks. Don't miss this chance to build connections and have fun!
Students and postdoctoral researchers are asked to register for the event for a 10€ fee. Senior attendees will be invited to the event and do not need to register.
The number of participants is limited.
Things to do in Berlin
Berlin, a city rich in history and culture, offers a vibrant tapestry of art and architecture. From its iconic landmarks to hidden gems, Berlin’s streets tell stories of its tumultuous past and dynamic present. Explore the capital’s diverse neighborhoods, each with its own unique flavor, through a variety of guided tours that cater to all interests.
Information pursuant to Sect. 5 German Telemedia Act (TMG)
Humboldt – Universität zu Berlin
School of Business and Economics
Chair of Statistics
Unter den Linden 6
10099 Berlin https://desbi.de/
VAT ID
Sales tax identification number according to Sect. 27 a of the Sales Tax Law:
DE 137176824
Web content manager
Stephen Schüürhuis, Erin Dirk Sprünken, Uwe Schöneberg
Institute of Biometry and Clinical Epidemiology
Charité - Universitätsmedizin Berlin
Charitéplatz 1
10117 Berlin
Germany